

Mobile indie game developers have begun to gain an edge by applying the experimentation tools from the Google Play Console and Firebase like A/B testing, but these out-of-the-box tools leave much potential on the table. Machine learning, combined with experimentation in gaming apps, provides a massive boost in optimization power when done right: ML maximizes the effectiveness of choices driven by your experiments for both large publishers with their numerous parallel experiments and indie game developers with their limited data by maximizing the utilization of available information.
First, a case study demonstrates how ML clarifies the results of an A/B test. I’ll show you how ML can make the most of the data you have to make better data-driven decisions faster, improving your game’s path to profitability.
Case Study: Banner Ads Timing
A common question is, “Should we show banner ads?” It is then followed by, “When?”
Consider the following example from real game data. The total number of samples is small for this indie developer (about 10,000 unique users). In this experiment, the timing of the appearance of banner ads is varied: ads either appear earlier in the user’s gameplay or later (specific numbers have been hidden to protect the data from our partner). When plotting the impact of this decision on LTV from Firebase experiments directly, it’s hard to say whether it’s best to show banner ads earlier, later, or sometime in-between:
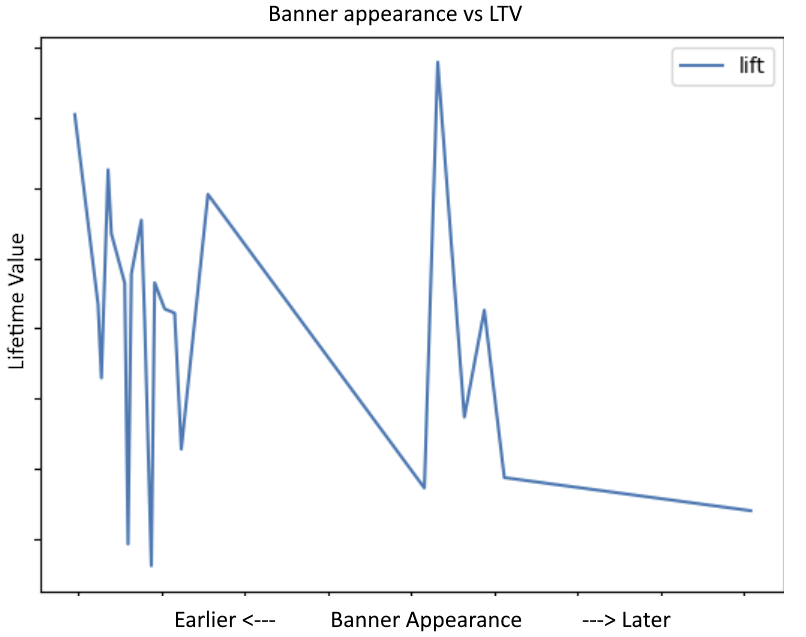
Machine learning enters the picture: additional information is accounted for, and the modeled impact of this parameter choice becomes much more clear after controlling for additional key variables like country and the other parallel experiments we were running:
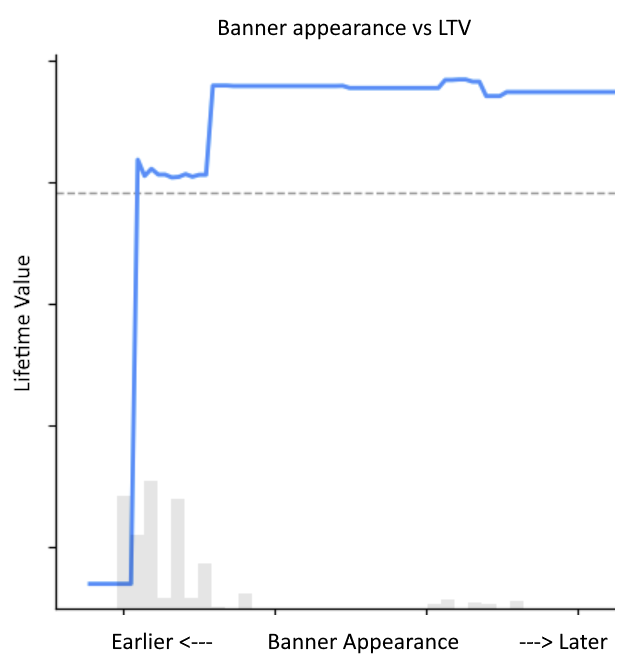
For this game, it’s clearly best to show banners later. A more subtle takeaway is that further experimentation should take place much later to see exactly how late banners can be introduced, considering the tradeoff between ads and user experience. This enjoyment of the game can be part of the model’s compound objective, or considered independently. Baking things like user feedback and engagement into the model would lead to an even later preference for the banner in this game to appear in the model’s timing recommendation.
The broader takeaways are:
- Direct interpretation of A/B testing data is much less clear, since the data from a classic A/B test doesn’t control for context, the amount of data per sampled point, or the nature of a continuous parameter and the ability of nearby experiments with similar values to inform the overall best value.
- Better choices can be made with less data using machine learning; you don’t need to “reach statistical significance” in Firebase to realize the benefits of experimentation. Statistical significance is the wrong meta-objective! You should be aiming for optimization.
Benefits Unlocked by ML
Adding ML to the experimental setup unlocks:
- Continuous Optimization
- Continuous Parameter Interpretation
- Contextual Information
- Cumulative Learning
Continuous Optimization
Firebase experiments do not implement continuous optimization: rather than continuing to use data to converge on the optimal solution, parameters that are suboptimal will continue to be explored throughout the duration of the experiment. By contrast, a continuous optimization can increasingly select optimal parameters in a manner such that your system begins to benefit early on and even more so later, without throwing out data from earlier experiments. As context changes (other experiments running; your UA strategy and user demographics; market conditions), your optimal continuous optimization will make use of this all. In the above banner ads experiment, optimization will continue to take place with more preference toward later times as the global optimal across all parameters converge to the best, while the model retains memory of historical results between experiments.
Continuous Parameter Interpretation
Firebase experiments have no concept of continuous variables, which means that you will be choosing between a discrete number of variables with an explicit tradeoff in statistical power, using the default A/B testing approach. By contrast, domain knowledge of the meaning of an experimental variable means you can treat it as a single parameter that likely has a single global maximum: rather than say, 20 parameter values, spread thin across 20 experiments with minimal statistical power, you have one parameter with a smooth curve (called partial dependence) from which the system can sample the best points.
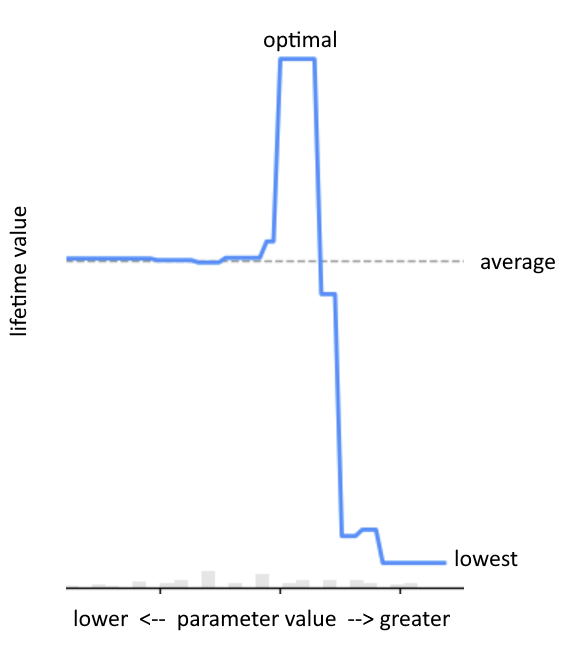
Contextual Information
Firebase experiments do not consider interaction and optimization across other running experiments. It’s helpful to control for variables outside of the experiment. This is done by random assignment in Firebase; however, other information is not utilized in this setup. Your results will arrive slowly.
Examples
- You already know that users in the United States monetize better than India, but does your A/B test leverage this information? A good model will control for these features to learn more efficiently (with less data) than one that does not.
- Other experimental variables may dominate your objective function, but are their effects considered when running multiple experiments in parallel? Not in Firebase.
- App version and time period need to be accounted for over long-running experiments.
Cumulative Learning
Experiment data is largely wasted across subsequent Firebase Experiment iterations: data does not span from one experiment to the next in the Firebase UI. An improved solution compounds your data across experiments; it learns from the past to sample better in the future, converging upon a global optimal without requiring cold-starts each time.
Why Not Just Use Firebase Personalization?
The limitations of Firebase Personalization (p13n) are many; it is a product I have mostly given up on after much effort to make it work:
- It’s a buggy, neglected product; the UI has several bugs that lead to misleading or incorrect visualizations / takeaways, like showing results for the wrong data. I’ve reported several related bugs without any apparent resolution or work by the team.
- Goodheart’s Law comes into play: when a measure becomes a target, it ceases to be a good measure. However, combined revenue targets and objectives e.g. pLTV (predicted lifetime value) and user feedback are not supported, yet they are important for avoiding perverse optimizations; even if you are a paperclip factory, your goal is not to maximize paperclips at the expense of everything else. In Firebase p13n, a single predefined target is supported, and manual monitoring of other metrics is offered. Note: a hack to get around this exists, but I don’t have any further room in the margins to include it here.
- Continuous variables are not implemented – there is no way to specify a range boundary; instead, a contextual multi-armed bandit implementation appears to naively assume categorical values. (This is why there is another limitation of only 5 variants).
- Interactions between parallel experiments and personalizations may not be implemented. External experiments being run are unlikely to be considered as context without special engineering efforts.
- Changing the parameters, e.g. value boundaries, results in throwing out all old data. The experiment restarts.
- The optimization power will be reduced (relative to a custom ML solution) since they (presumably) do not control for known information prior to the experiment’s start, e.g. pLTV | D1 – the predicted lifetime value known by day 1.
- Activation events (as seen in Firebase experiments) are not available, but are usually relevant to the optimization. An activation event is a trigger that determines which data to count in the model.
- Fixed 24 hour periods are set as the stickiness window for the parameter, even if this is not desired. Sometimes, a lifetime window is preferable; your users might not respond well to changing pricing or rewards every day on them.
Despite all these limitations, for straightforward use cases, a drop-in personalization solution with all the above limitations might be better than nothing, as long as it is implemented correctly. Implemented Correctly is still a nontrivial job for the average indie game developer, given the caveats and gotchas that they will likely not be aware of.
Final Thoughts: The Future of Custom Personalization
The post largely covered ML on top of Firebase experimentation. Going further, customized personalization tailored to the app and its remote config nuances can really eek out maximum performance, considering conditional optimizations as opposed to global optimizations, which A/B testing emphasizes. For example, why not vary ad frequency differently in different geos that have different receptivity to ads? This is where heavy engineering efforts come into play, along with a data science team or ML engineer; it is not for the faint-hearted solo indie developer, who is better-served focusing on their core gameplay mechanics. Global optimization still has its place, for example when a design decision requires fixing a choice to a specific value for all users globally.
The future of optimization in an ecosystem with increasingly-challenging UA feedback loops (privacy) means that emphasis on personalization is expected to pay large dividends; in-game optimization is a focus of Quantified Publishing.
Contact Brian
Liked my post? Have any feedback? I want to hear your thoughts!
- Connect with me (Brian) on LinkedIn
- Give my post a Like on LinkedIn!
- Are you an indie game developer? Apply to partner up!